Making Beautiful API Keys

tl;dr - Since developers are our customers, we wanted them to have beautiful API keys. We couldn't find a suitable standard solution so we made our own package - uuidkey - that you can use to encode & format UUIDs into human-readable keys. If you use UUIDv7, you can also decode the keys to store them as sortable, indexable IDs in your database.

An example API key generated by github.com/gofrs/uuid and encoded with github.com/agentstation/uuidkey.
Update 01/11/2025: In the 24 hours since we published this article, there's been some amazing discussion, support, and feedback. Here are some notes on what we've learned, and how we are updating uuidkey based on developer feedback:
-
Dashes: The ability to double-click to copy, which was lost with the addition of dashes, was more important to developer commenters than we thought it'd be (even if only needed once). We heard you, so we've already updated uuidkey to support a
WithoutHyphensoption for theEncodefunction so you can generate keys without dashes. -
Entropy: Some folks were worried that our resulting key after encoding has fewer bits of entropy compared to the original UUID. The Crockford base32 encoding does not reduce entropy, it is a 1:1 mapping. We did however learn that the UUID spec warns against using UUIDv7 (only 74 bits of entropy) and even UUIDv4 (standard 122 bits of entropy) alone for API Keys. We plan on still supporting UUIDv7 and UUIDv4, but will add additional entropy bits to follow the official recommendation.
-
Prefixes: Some folks suggested adding prefixes, which make it easier to identify & search for keys (particularly to ensure they don’t get accidentally committed to a repo). We plan to add an option for that to
uuidkey. Worth mentioning that a few folks pointed us to Github's auth token implementation that includes prefixes, which is a great reference standard.
The Problem
API keys are a large part of a user's first interaction with our product, and we want to make a good impression. We want to make our keys look good and "feel" good, but there seems to be no "good" standard in the industry.
We are a busy startup, but we are also a developer-first platform company. Therefore, we thought it made sense to put some time, thought and effort into figuring out a solution we (and hopefully our developers) would be happy with.
Most API Keys Suck
We came up with a list of requirements for our API keys:
- Secure
- Globally unique
- Sortable
- Performant in Postgres
- Nice to look at
Unfortunately, most API keys are ugly. They're often just random strings of characters with inconsistent formatting, making them hard to read, sort, and identify.
Ugly API keys in the wild.
As most beautiful things in life are symmetrical - we wanted to bring symmetry to our API keys.
The IDs we Rejected
-
Integers and Bigints
Simple, readable, and easy to sort. But they reveal how many keys exist and are easily guessable - not great for security.
-
NanoIDs
NanoIDs offer fully random, customizable IDs. They're particularly suited for public-facing identifiers (we even use them for our public IDs1). But they lack timestamp information that's useful for sorting and debugging.
id, _ := publicid.New()
fmt.Println("Generated default public ID:", id)
// Output: Generated default public ID: Ab3xY9pQ
A NanoID generated using our publicid package.
-
UUIDs
UUIDs are the industry standard, with two versions worth considering for API keys2:
- UUIDv4: Purely random characters. Simple but effective.
- UUIDv7: Includes timestamps, which we love because:
- It embeds creation time, useful for debugging without database lookups
- It enables efficient database queries and chronological sorting.
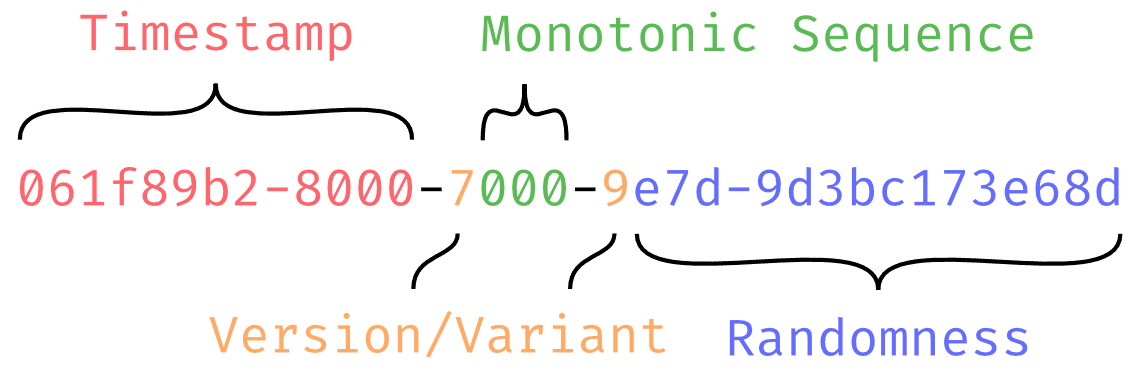
UUIDv7 example. Image is from Dave Allie's blog.
Overall, developers like to use UUIDs - they just don't like how they look.

An X User with similar complaints.
-
ULIDs
ULIDs were close to what we wanted. They include timestamps and use Base32 encoding for better readability. But we preferred UUID's native Postgres support (more on this below), and were still not quite satisfied with the aesthetics.
ulid.New().String() // 01H9ZQPS8ZQXV4RNJQ6PDNQ4FX
ULID example
Our Solution
As none of the options were sufficiently beautiful (symmetrical), we created our own approach:
- Use UUIDv7 as the base ID to leverage timestamps
- Encode the ID using Crockford Base32 for readability
- Add artfully placed dashes for aesthetics
The result:
key, _ := uuidkey.Encode("d1756360-5da0-40df-9926-a76abff5601d")
fmt.Println(key) // Output: 38QARV0-1ET0G6Z-2CJD9VA-2ZZAR0X
Our final encoded keys
Our keys are:
- 31 characters (28 without dashes) vs UUID's 36
- Highly readable segments with 4 sets of 7 uppercase letters and numbers for "blocky" aesthetics and readability
- Chronologically sortable when stored decoded as UUIDs
- Obfuscated timestamps in the user-facing key (but yes a savvy user could still decode it). We find timestamp metadata in the key to be a bonus, you can always use UUIDv4 instead! You do you boo! 👻
Why UUIDv7?
Beyond the timestamp benefits, UUIDv7 will get native Postgres support in v183. While you can use extensions to generate UUIDv7s server side for now, the native Postgres support will certainly be more performant4, and will work great to pass to uuidkey.Encode().
For our implementation, we're currently generating keys in the application layer and storing them as UUIDs for sorting and indexing. Once Postgres v18 is released, we'll switch to Postgres generation to offload that dataflow from our application layer and have slightly better performance.
Why Crockford Base32?
We chose Crockford Base32 encoding because it:
- Uses only uppercase letters and numbers, which improves readability5
- Reduces key length by ~1/5
- Mapping is performant and predictable
Why Dashes?
The resulting dashed keys are "blocky" and symmetrical. If you were to gray out the individual characters, they almost look like a barcode. We think it makes it easy to quickly read portions of a key to identify it.
We may have been subconsciously inspired by old school product CD keys:

Brings you back.... Image is from eBay.
The dashes do remove easy double-click copying, but we think this a fine trade off for readability. We don't want users copying and pasting them everywhere, in fact we want them to be handled with care. Ideally, users copy each key exactly once - when they generate the key from our dashboard - so we added a copy button to our UI to solve that case.
The uuidkey Package
We open sourced these design choices at github.com/agentstation/uuidkey. If you agree with our aesthetics, reasoning, symmetry, and want beautiful API keys of your own, you are welcome to play around with our open source project.
The heart of the uuidkey package encodes UUIDs to a readable Key format via the Base32-Crockford codec and also decodes them back to UUIDs.
Encode
// Encode will encode a given UUID string into a Key with basic length validation.
func Encode(uuid string) (Key, error) {
if len(uuid) != UUIDLength { // basic length validation to ensure we can encode
return "", fmt.Errorf("invalid UUID length: expected %d characters, got %d", UUIDLength, len(uuid))
}
// select the 5 parts of the UUID string
s1 := uuid[0:8] // [d1756360]-5da0-40df-9926-a76abff5601d
s2 := uuid[9:13] // d1756360-[5da0]-40df-9926-a76abff5601d
s3 := uuid[14:18] // d1756360-5da0-[40df]-9926-a76abff5601d
s4 := uuid[19:23] // d1756360-5da0-40df-[9926]-a76abff5601d
s5 := uuid[24:36] // d1756360-5da0-40df-9926-[a76abff5601d]
// decode each string part into uint64
n1, _ := strconv.ParseUint(s1, 16, 32)
n2, _ := strconv.ParseUint(s2+s3, 16, 32) // combine s2 and s3
n3, _ := strconv.ParseUint(s4+s5[:4], 16, 32) // combine s4 and the first 4 chars of s5
n4, _ := strconv.ParseUint(s5[4:], 16, 32) // the last 8 chars of s5
// encode each uint64 into base32 crockford encoding format
e1 := encode(n1)
e2 := encode(n2)
e3 := encode(n3)
e4 := encode(n4)
// build and return key
return Key(e1 + "-" + e2 + "-" + e3 + "-" + e4), nil
}
Decode
// Decode will decode a given Key into a UUID string with basic length validation.
func (k Key) Decode() (string, error) {
if len(k) != KeyLength { // basic length validation to ensure we can decode
return "", fmt.Errorf("invalid Key length: expected %d characters, got %d", KeyLength, len(k))
}
// select the 4 parts of the key string
key := string(k) // convert the type from a Key to string
s1 := key[0:7] // [38QARV0]-1ET0G6Z-2CJD9VA-2ZZAR0X
s2 := key[8:15] // 38QARV0-[1ET0G6Z]-2CJD9VA-2ZZAR0X
s3 := key[16:23] // 38QARV0-1ET0G6Z-[2CJD9VA]-2ZZAR0X
s4 := key[24:31] // 38QARV0-1ET0G6Z-2CJD9VA-[2ZZAR0X]
// decode each string part into original UUID part string
n1 := decode(s1)
n2 := decode(s2)
n3 := decode(s3)
n4 := decode(s4)
// select the 4 parts of the decoded parts
n2a := n2[0:4]
n2b := n2[4:8]
n3a := n3[0:4]
n3b := n3[4:8]
// build and return UUID string
return (n1 + "-" + n2a + "-" + n2b + "-" + n3a + "-" + n3b + n4), nil
}
A big shoutout to richardlehane/crock32 for the solid implementation of encoding and decoding crockford base32 operations.
The package is designed to work with any UUID that follows the official UUID specification (RFC 4122), but we specifically test and maintain compatibility with the two most popular UUID Go generators:6
Installation is straightforward:
go get github.com/agentstation/uuidkey
Basic usage:
key, _ := uuidkey.Encode("d1756360-5da0-40df-9926-a76abff5601d")
fmt.Println(key) // 38QARV0-1ET0G6Z-2CJD9VA-2ZZAR0X
We've put in effort to keep the overhead minimal:
BenchmarkValidate-12 33527211 35.72 ns/op
BenchmarkParse-12 32329798 36.96 ns/op
BenchmarkEncode-12 3151844 377.0 ns/op
BenchmarkDecode-12 5587066 216.7 ns/op
Select performance benchmarks - your mileage may vary.
Contributing to uuidkey
We're committed to maintaining uuidkey as a reliable open source tool since we use it in production - contributions are welcome!
If you find it useful or have ideas for improvements, we'd love to hear from you in our GitHub issues or Discord community.
🎨 Prior Art & Shoulders of Giants
After we published our project, we found a few others with similar implementations but still lacked meeting our criteria for encoding and decoding UUIDs using Go.
- uuidapikey - Go, but does not support encoding or decoding UUID input
- based_uuid - Ruby, but for Public IDs
Wrap Up
At AgentStation, we're building a platform where AI agents get their own virtual workstations to run browsers, join meetings, and execute code. As we scale to thousands of workstations, having sortable, performant keys is practical infrastructure.
But we also believe developers appreciate beautiful symmetrical things like we do, even API keys.
We hope you find uuidkey useful and beautiful.
Want to build AI agents with us? We're taking beta users. Sign up for early access.
Footnotes
-
We opened sourced our package, publicid, for generating and validating NanoID strings designed to be publicly exposed. ↩
-
There's actually eight versions of UUIDs, but all of them suck except for v4 and v7:
- UUIDv1: Based on timestamp and MAC address. These are particularly bad since MAC addresses can be used to track devices. Plus, if you're generating UUIDs across multiple machines, you need to ensure each has a unique MAC address or risk collisions. Uses node identifiers and nanosecond precision timestamps.
- UUIDv2: This version was never fully standardized and is practically unused. It was supposed to be for DCE Security, but nobody actually implements it.
- UUIDv3: Uses MD5 hashing of a namespace and name. It's deterministic, which means if someone knows your namespace and name, they can recreate your IDs.
- UUIDv4: Based on random characters. Random is nice, very low likelihood of collisions.
- UUIDv5: Similar to v3 but uses SHA-1 instead of MD5. SHA-1 is better than MD5, but the deterministic nature still makes it a no-go for API keys.
- UUIDv6: A k-sortable id based on timestamp, and field-compatible with v1. It's a better v1, but still contains the MAC address privacy issues. Like v1, it uses node identifiers and nanosecond precision timestamps.
- UUIDv7: A k-sortable id based on timestamp. Instead of tracking nodes and nanoseconds, it uses millisecond precision (because let's be real, that's what most systems have) and throws in 74 random bits to avoid collisions. If you've got better clocks, you can trade 12 of those random bits for more precise timing or sequence numbers.
- UUIDv8: A "custom" UUID format that lets you define your own timestamp format and bit layout. It's meant for cases where other versions don't quite fit your needs - like if you need a different timestamp precision or want to embed additional data.
-
UUIDv7 support was supposed to be included in v17, but the RFC wasn't finalized in time. Sad! ↩
-
Dave Allie's blog post on his ULID implementation shares a benchmark of the performance of a custom function for generating ULIDs versus the native Postgres
gen_random_uuid()function, which generates UUIDv4. The custom function was 73% slower in generating 10 million values, and 31% slower when generating and inserting 1 million values. While we don't know how UUIDv7 will perform natively, it's likely to be faster than a custom function or extension. ↩ -
The Crockford Base32 encoding uses a 32 character symbol set - all 10 digits, and 22/26 capital letters, excluding I, L, O, and U. It was designed to allow for verbal communication of public keys, which is why letters that can be confused with numbers were removed (0 and O, I/l and 1). Allegedly, U was removed to reduce the chance of "accidental obscenity", but we suspect it was because Crockford wanted an even 32 symbol set. ↩
-
Historically, people loved the Google package because it just worked. However, after years of wear and tear with many different UUID key versions it's API patterns became a bit of a mess to use. ↩